[Dissertation] Interpretable Machine Learning in Natural Language Processing for Misinformation data
Masters dissertation by Yolanda Nkalashe, Faculty of Engineering, Built Environment and Information Technology University of Pretoria, Pretoria
Members
Yolanda Nkalashe, MITC Big Data Science
Supervisor(s)
Prof. Vukosi Marivate
Abstract
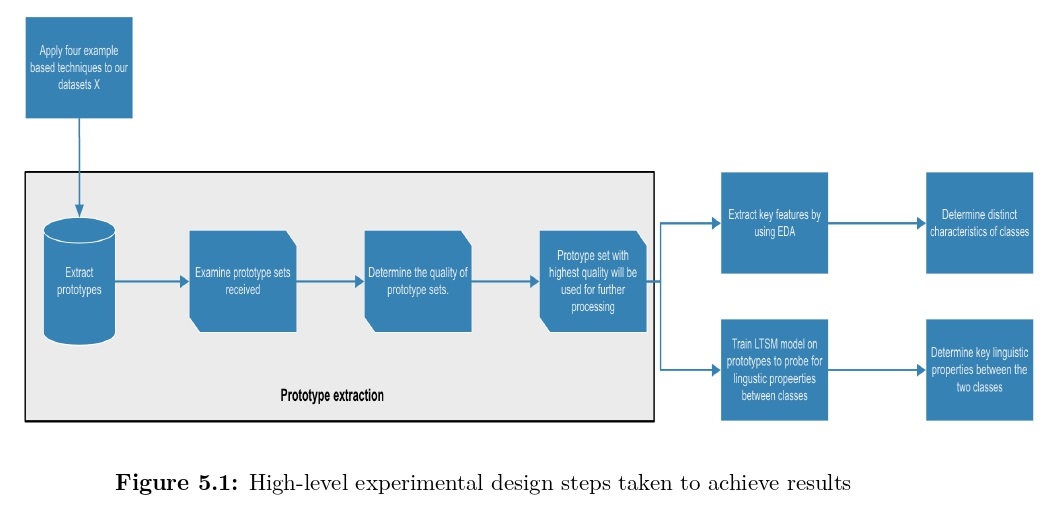
The interpretability of models has been one of the focal research topics in the machine learning community due to a rise in the use of black box models and complex state-of-the-art models . Most of these models are debugged through trial and error, based on end-to-end learning . This creates some uneasiness and distrust among the end-user consumers of the models, which has resulted in limited use of black box models in disciplines where explainability is required . However, alternative models, “white-box models,” come with a trade-off of accuracy and predictive power . This research focuses on interpretability in natural language processing for misinformation data. First, we explore example-based techniques through prototype selection to determine if we can observe any key behavioural insights from a misinformation dataset. We use four prototype selection techniques: Clustering, Set Cover, MMD-critic, and Influential examples. We analyse the quality of each technique’s prototype set and use two prototype sets that have the optimal quality to further process for word analysis, linguistic characteristics, and together with the LIME technique for interpretability. Secondly, we compare if there are any critical insights in the South African disinformation context.