[Dissertation] Exploring Cross-Lingual Learning Techniques for advancing Tshivenda NLP coverage
Masters dissertation by Ndamulelo Nemakhavhani, Faculty of Engineering, Built Environment and Information Technology University of Pretoria, Pretoria
Members
Ndamulelo Nemakhavhani, MITC Big Data Science
Supervisor(s)
- Dr. Vukosi Marivate
- Dr. Jocelyn Mazarura
Abstract
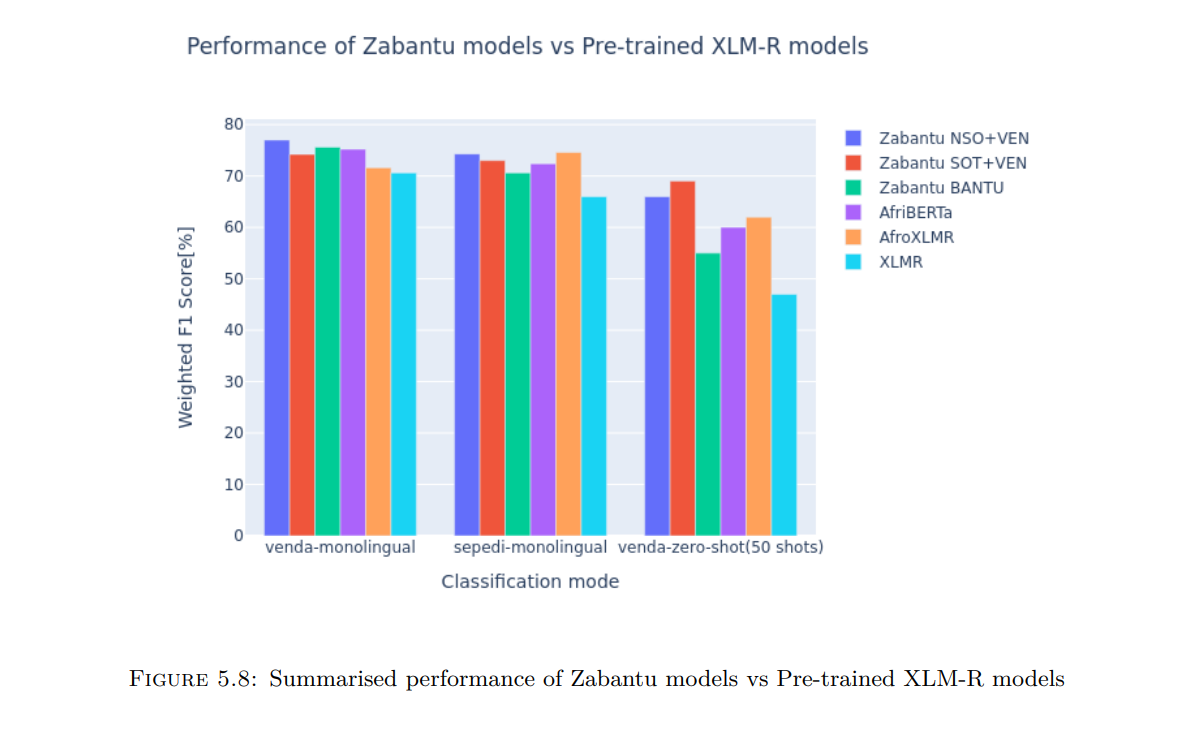
The information age has been a critical driver in the impressive advancement of Natural Language Processing (NLP) applications in recent years. The benefits of these applications have been prominent in populations with relatively better access to technology and information. On the contrary, low-resourced regions such as South Africa have seen a lag in NLP advancement due to limited high-quality datasets required to build reliable NLP models. To address this challenge, recent studies on NLP research have emphasised advancing language-agnostic models to enable Cross-Lingual Language Understanding (XLU) through cross-lingual transfer learning. Several empirical results have shown that XLU models work well when applied to languages with sufficient morphological or lexical similarity. In this study, we sought to exploit this capability to improve Tshivenda NLP representation using Sepedi and other related Bantu languages with relatively more data resources. Current state-of-the-art cross-lingual language models such as XLM-RoBERTa are trained on hundreds of languages, with most being high-resourced languages from European origins. Although the cross-lingual performance of these models is impressive for popular African lan- guages such as Swahili, there is still plenty of room left for improvement. As the size of such models continues to soar, questions have been raised on whether competitive performance can still be achieved using downsized training data to minimise the environmental impact yielded by ever-increasing computational requirements. Fortunately, practical results from AfriBERTa, a multilingual language model trained on a 1GB corpus from eleven African languages, showed that this could be a tenable approach to address the lack of representation for low-resourced languages in a sustainable way. Inspired by these recent triumphs in studies including XLM-RoBERTa and AfriBERTa, we present Zabantu-XLM-R, a novel fleet of small-scale, cross-lingual, pre-trained language models aimed at enhancing NLP coverage of Tshivenda. Although the study solely focused on Tshivenda, the presented methods can be easily adapted to other least-popular languages in South Africa, such as Xhitsonga and IsiNdebele. The language models have been trained on different sets of South African Bantu languages, with each set chosen heuristically based on the similarity to Tshivenda. We used a novel news headline dataset annotated following the International Press Telecommunications Council(IPTC) standards to conduct an extrinsic evaluation of the language models on a short text classification task. Our custom language models showed an impressive average weighted F1-score of 60% in few- shot settings with as little as 50 examples per class from the target language. We also found that open-source languages like AfriBERTa and AFroXLMR exhibited similar performance, although they had a minimal representation of Tshivenda and Sepedi in their pre-training corpora. These findings validated our hypothesis that we can leverage the relatedness among Bantu languages to develop state-of-the-art NLP models for Tshivenda. To our knowledge, no similar work has been carried out solely focusing on few-shot performance on Tshivenda.