DSFSI Summer Research Experience: Fine-tuning Multilingual Pre-trained African Language Models
Rozina Myoya and Fiskani Banda - The aim of the research was to explore the application of Pre-trained Language Models(PLMs) on a multilingual classification task. The study concluded that PLMs perform best on downstream tasks on the languages they were pre-trained on, thus emphasising the importance of including low resource languages in the pre-training process of LMs.

Summary and Introduction to the research
The aim of the research was to explore the application of Pre-trained Language Models(PLMs) on a multilingual classification task. We attempted to answer the research question: Can we train PLMs on low-resource languages (LRLs) (e.g., South African Language) to perform well on downstream tasks such as classification? To answer this question, three PLMs were considered, namely AfriBERTa, AfroXLMR and AfroLM to run the experiment to improve the performance of NLP applications without changing the model through data pre- and post-processing that is usually done in machine translation. The study concluded that PLMs perform best on downstream tasks on the languages they were pre-trained on, thus emphasising the importance of including low resource languages in the pre-training process of LMs. Data augmentation techniques, such as random text rearrangement proved beneficial for enhancing model performance, it is safe to assume that with advanced methods of data augmentation the models would produce even better results. Future research can focus on investigating the use of a mix of PLMs to improve the performance of source and target language tasks that come after classification.
Why is it important
Currently, there has been accelerated growth in Natural language processing with regard to the application of models such as Neural Machine Translation. These models perform sup-optimally on low-resource language pairs compared to its high-resource counterparts. The main reason for this is due to the unavailability of large parallel corpora for low-resource languages. This limitation has led to the emergence of research on topics focused on NLP applications using LRLs. Despite the availability of the pre-trained language models (PLMs), for small and medium-sized industries with insufficient hardware, there are many limitations in servicing the latest PLMs based NLP application software due to slow speed and insufficient memory. Because these techniques typically necessitate large amounts of data, they are much more difficult to service with PFA, particularly for low-resource languages. For this reason, the development of new methods for processing low-resource language pairs is still in its infancy, but researchers are beginning to explore alternative approaches such as transfer learning, multi-task learning, and pre-training that can help improve the NMT for downstream tasks with a small amount of data.
Information about the Summer experience program
The research experience program was started within the DSFSi research group in Winter (June-July 2022) to expose students to research through working with DSFSI group members on different research projects. With the Summer edition, we successfully concluded the first year of the program. This blog post goes into the technical details of the research of one of the student teams. We acknowledge the support of NVIDIA (Hardware grant for GPUs), ABSA (through the ABSA UP Data Science Chair funding for remuneration of the students), Tensorflow for funding for research costs. If you would like to support the sustainability of this program and expansion for the future, please get in touch with Prof Vukosi Marivate vukosi.marivate@cs.up.ac.za
Research details
Two labelled datasets were used to fine-tune the Pre-trained Language Models: an isiZulu News dataset and the African News Topic Classification (ANTC) dataset. From these 2 datasets, 6 languages were included , which were isiZulu, Lingala, Malagasy, Nigerian Pidgin and Somali. These languages fall into 4 language families : Afro-Asiatic (Somali) , Niger Congo(isiZulu and Lingala) , English Creole (Nigerian Pidgin) and Malayo-Polynesian (Malagasy). This indicated the diversity that was present in the data given that the different language families have different linguistic characteristics.
All the models were evaluated on the NLP downstream task of news topic classification. The evaluation consisted of assessing how each individual language performed when trained and validated by the different PLMs. The F1-score was used to compare the results during the experimentation. The experimentation process followed was divided into 3 steps:
- Training the PLMs and getting the baseline performance of each language.
- Investigating the different ways to improve the models performance through modifying the data and the model architecture parameters.
- Evaluating the model’s performance and the results obtained.
To get the optimal model hyperparameters which were required for the different PLMs , Ray-tune (python library) was used. This was done when establishing the baseline for each of the PLMs.
All the experimentation was carried out mainly on the isiZulu News Dataset. The first part of the experiment involved modification of the model’s architecture parameters. This method explored freezing the models’ encoder layers(lower layers), except for the classifier layer. This meant that the only parameters that changed were the classifier layer which was initialised and adjusted accordingly. Furthermore, different learning rates were considered to determine the optimal rate that would result in the best performance.
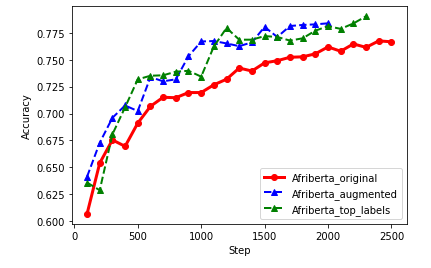
For the data modification of the experiment, two different methods were considered. The first method was considered due to the uneven distribution of the different classes. Due to this uneven distribution , it was decided to only use the top 10 classes for the fine-tuning process. The other method that was considered was increasing the number of samples for each of the classes through text augmentation techniques. For the augmentation process, both random character level and token level text augmentation was considered. The new augmented data contained samples which were based on a combination of swapping around or deleting characters and random sampling.
Significant Results
- The results obtained after the experimentation and training of the models on the different languages showed that the models performed best in the classification tasks on languages they were originally pre-trained on. This highlights the importance of the inclusion of “low-resource” languages in pre-training LMs.
Table 1: Baseline performance of models based on F1 score
| Dataset | Language | AfriBERTa | Afro-XLMR | AfroLM |
|---|---|---|---|---|
| isiZulu News | isiZulu | 0.506 | 0.695 | 0.616 |
| siSwati | 0.438 | 0.563 | NA | |
| ANTC | isiZulu | 0.825 | 0.854 | 0.832 |
| Lingala | 0.618 | 0.607 | 0.664 | |
| Malagasy | 0.524 | 0.682 | 0.512 | |
| Pidgin | 0.829 | 0.835 | 0.838 | |
| Somali | 0.78 | 0.682 | 0.751 |
- Data modification through augmentation improved model performance and further research can be carried out on how to conduct augmentation on African languages that includes lexical and context-based techniques instead of purely random rearrangement. Also, the models performed best when only the top 10 labels were included in the training process.
Table 2: Experimentation results of models based on the F1 score
| Experimentation | Dataset | Language | AfriBERTa | Afro-XLMR | AfroLM |
|---|---|---|---|---|---|
| Freezing lower layers | isiZulu News | isiZulu | 0.424 | 0.464 | 0.384 |
| Increasing the learning rate range | isiZulu News | isiZulu | 0.523 | 0.45 | 0.603 |
| Using the data in top 10 classes | isiZulu News | isiZulu | 0.514 | 0.771 | 0.643 |
| Augmented Data | isiZulu News | isiZulu | 0.538 | 0.724 | 0.591 |
Table 3: Results of the experimentation carried out on the combined dataset (F1 Score)
| Experimentation | Dataset | Language | AfriBERTa |
|---|---|---|---|
| Original | Combined_Dataset | All | 0.726 |
| Augmented Data | Combined_Dataset | All | 0.744 |
| Using the data in top 10 classes | Combined_Dataset | All | 0.745 |
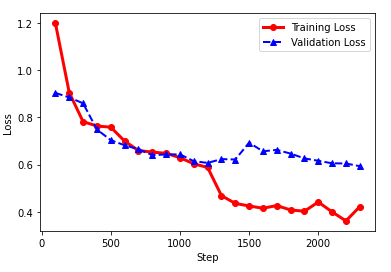
- These models would be ideal for application in environments that are short on resources and processing power. For example, the AfriBERTa model required only 1 epoch for the training process. The figure below shows the difference between training and validation loss for the AfriBERTa experimentation where only the top 10 labels were considered
Personal Takeaways from the Summer Research program
Fiskani
The summer research program has added a lot of value for me as a student. Firstly it has provided me with an opportunity to get my hands dirty and learn Natural Language Processing through doing a project. From this project , I have also learnt what research entails and what goes on behind the scenes when one says “Research”. At the end of this program, I have walked away with more knowledge, experience and eagerness to learn and do more in the Field of Natural Language processing.
Rozina
The Summer Research Program marked my first real foray into the field of real-world research in NLP. During this time, I had the opportunity to work alongside talented individuals who taught me invaluable lessons on the applications of deep learning and the potential of this field in empowering marginalised communities. Moreover, I developed an appreciation for the intangible aspects of machine learning applications, such as time management and budgeting, with regard to training models. Overall, I feel much more knowledgeable in the field of deep learning and NLP as a result of the exposure I received from the research program. Most importantly, I was able to see the relevance of these technologies within industries such as telecommunications, translation, and other client-facing service deliveries that require customer interaction.
Why would you suggest others apply for this position in the future?
Fiskani
I would suggest applying for this position because it gives you the opportunity to learn and engage with a project that you might otherwise have never done. It allows you to learn new things and get your hands dirty without the added pressure of getting marks at the end of this. Without this pressure , I feel you learn more about the field and also take advantage of the time to engage with the project and do research.
Rozina
I would definitely recommend others apply for this position in future because it is the perfect environment to test your knowledge of deep learning through practical problem solving. Also, it provides the perfect opportunity for developing or enhancing your research skills, including scientific writing, as evidenced by the research papers we produced at the end of the program. In addition to that, participation in the program provides valuable experience in research collaboration and how to effectively communicate your ideas using deep learning jargon. The experience is truly invaluable and presents the perfect opportunity to step out of your academic comfort zone and apply your theoretical knowledge to tangible, real-world scenarios.
Author Bios ?
Fiskani Banda
I am Fiskani Banda. I am currently an MIT Big Data Science student at University of Pretoria. I previously studied Biomedical engineering as well as Information engineering at the University of Witwatersrand. My passion for Data Science started in 2020 during my vacation work for the Wits Business Intelligence Services , where I was introduced to the fundamentals of all things data. My current interest is Natural language processing. I am keen to learn and do research in this field.
Rozina Myoya
I am Rozina Myoya. I am currently an MIT Big Data Science candidate at the University of Pretoria completing my final year. My research focuses on Natural Language Processing applications in the public transport space. I like to describe myself as a transport engineer turned data scientist, but in actuality, my work has always been centred around data science and its potential to enhance our society. I am excited to be a part of this ever-evolving field and witness the revolutionary changes that are yet to come.