[Dissertation] An investigation of the effectiveness of using Twitter data for predicting South African protests with Graph Neural Networks
Masters dissertation by Derwin Ngomane, Faculty of Engineering, Built Environment and Information Technology University of Pretoria, Pretoria
Members
Derwin Ngomane, MITC Big Data Science
Supervisor(s)
- Dr. Vukosi Marivate
- Dr. Maxamed Ahmed
Abstract
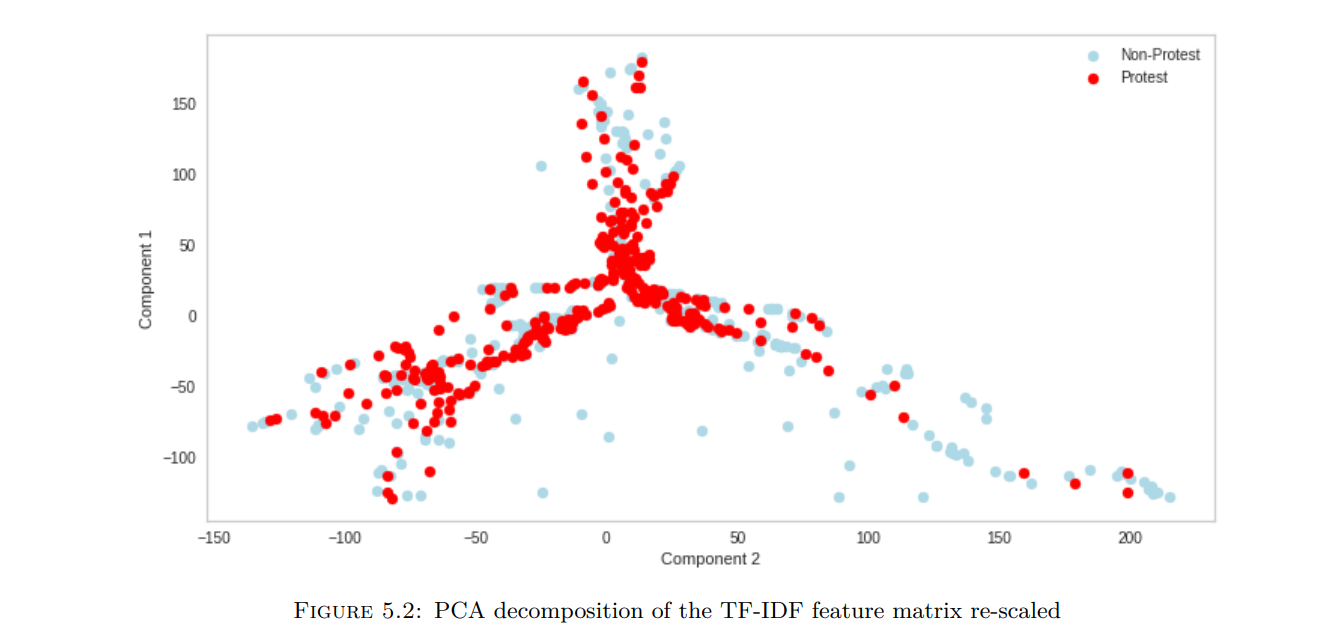
Social media creates an echo chamber effect that is closely related to social movement theory, which aims to mobilise people to change society. In South Africa, there has been an increase in protests that appear to have started on social media. For example, consider the riots that occurred in July 2021 following the arrest of former President Jacob Zuma. Protests in South Africa, on the other hand, have culminated in violent incidents, such as the July 2021 protest. In that situation, the South African Human Rights Commission found that social media sites such as WhatsApp, Facebook, and Twitter aided the violence by sharing protest information. This study investigates whether social media can be utilised to signal upcoming South African protests. This research investigates the effectiveness of nose reduction techniques on Twitter data for predicting protest-related events in South Africa using Graph Neural Networks. It addresses research gaps by addressing the need for graph-based methodologies in the South African context, addressing the lack of noise reduction research for Twitter data, and using an automated method to extract relevant keywords in the word networks. The work aims to provide a new avenue for noise reduction in real-world scenarios where future events have not occurred. This study examines a three-year data window between 2019 and 2021 using the Global Dataset of Events, Location, and Tone (GDELT) and Twitter data. GDELT focuses on CAMEO codes related to protests and conflict, while Twitter extracts social media text related to protest-related posts. A sliding window approach is used to combine the data, with noise-reduction filtration techniques guiding the filtration. This work explores the potential of processing Twitter data to reveal signals for improved predictive capability. Derivative metrics, from hashtags, links, and mentions, are used to reveal such signals. The study compares different machine learning methods, including Logistic Regression, Graph Convolutional Networks, and Graph Isomorphism Networks, to model the data. It is discovered that the geometric deep learning methods struggle with overfitting in hold-out testing data but are stable and have better cross-validation scores. The GIN model exhibits higher accuracy and isomorphism detection, making it suitable for the task. However, graph neural networks struggle with limited data and hence overfit the training data, as well as isomorphism and isolated nodes due to message-passing paradigm. The intricacy of Twitter interactions and conversations is highlighted in this work, empha- sising the need for future research in data processing and model building. The study excluded other data features to add more information about the data space’s complexity, such as user interactions. Keyword selection was done independently, but node eigenvector centrality could be used for informed decision-making. The graph neural network paradigm of message passing has limited capability in the existence of isolated nodes, and isomorphism is crucial for network performance. Further research should investigate dynamic capabilities and edge weights in GIN networks.